As businesses increasingly adopt microservices and serverless architectures, managing fluctuating workloads efficiently becomes crucial. Kubernetes autoscaling has long been a staple for optimizing resources, but what about scaling applications dynamically based on real-time events, like messages in queues or database updates? Enter KEDA (Kubernetes Event-driven Autoscaling), a lightweight tool that makes scaling Kubernetes workloads seamless, cost-effective, and truly event-driven.
What is Scaling?
Kubernetes autoscaling automatically adjusts the number of nodes or pod resources in a cluster based on demand. Scaling refers to changing the number of pod replicas to ensure application performance and availability.
- Manual Scaling: You use the kubectl scale command to manually set the number of replicas.
- Autoscaling: Kubernetes adjusts the number of pods or resources automatically based on metrics like CPU usage or custom application metrics.
Types of Scaling in Kubernetes
- Horizontal Pod Autoscaler (HPA):
- Adjusts the number of pods based on metrics like CPU, memory, or custom values.
- Continuously monitors metrics and modifies replica counts dynamically.
- Vertical Pod Autoscaler (VPA):
- Optimises resource usage by adjusting the CPU and memory settings of pods.
- Useful for applications with variable resource needs, though it requires additional setup.
- Cluster Autoscaler:
- Manages the number of nodes in the cluster.
- Adds nodes when resources are insufficient and removes them when underutilised.
- Works with cloud providers like AWS, GCP, or Azure.
Example: You can set an HPA to maintain CPU usage at 50%, scaling replicas between 1 and 10.
What is KEDA?

KEDA (Kubernetes-based Event-Driven Autoscaler) is an open-source, lightweight tool designed to scale Kubernetes workloads based on external events or triggers, such as messages in queues, database records, or HTTP requests. Unlike traditional Kubernetes autoscaling, which relies on metrics like CPU and memory usage, KEDA allows you to scale pods dynamically based on real-time events that need processing.
Key Features of KEDA:
- Event-Driven Scaling: Scales workloads based on custom triggers from external sources like Azure Event Hubs, Kafka, RabbitMQ, or custom metrics.
- Seamless Integration: Works alongside Kubernetes' Horizontal Pod Autoscaler (HPA), enhancing its functionality without duplication or conflict.
- Flexibility: Lets you target specific applications for event-driven scaling while leaving others unaffected.
- Lightweight: A simple, single-purpose component that can easily integrate into any Kubernetes cluster.
How Does KEDA Work?
KEDA works by monitoring external event sources, like message queues or databases, to decide when to scale applications. It integrates with the Kubernetes API to register scaling rules and provides metrics to the Horizontal Pod Autoscaler (HPA). When an event triggers, KEDA scales the workload up or down by adjusting the number of pods or even scaling down to zero when idle. This ensures applications scale dynamically based on real-time demand while optimizing resource usage.
Why use KEDA?
- Cost-Effectiveness: By scaling to zero when there’s no activity, KEDA reduces resource usage and costs.
- Flexibility: Works with a variety of external event sources, allowing you to create custom and dynamic scaling rules for your applications.
- Real-Time Scaling: Ideal for event-driven applications with fluctuating workloads, ensuring optimal resource allocation.
Architecture
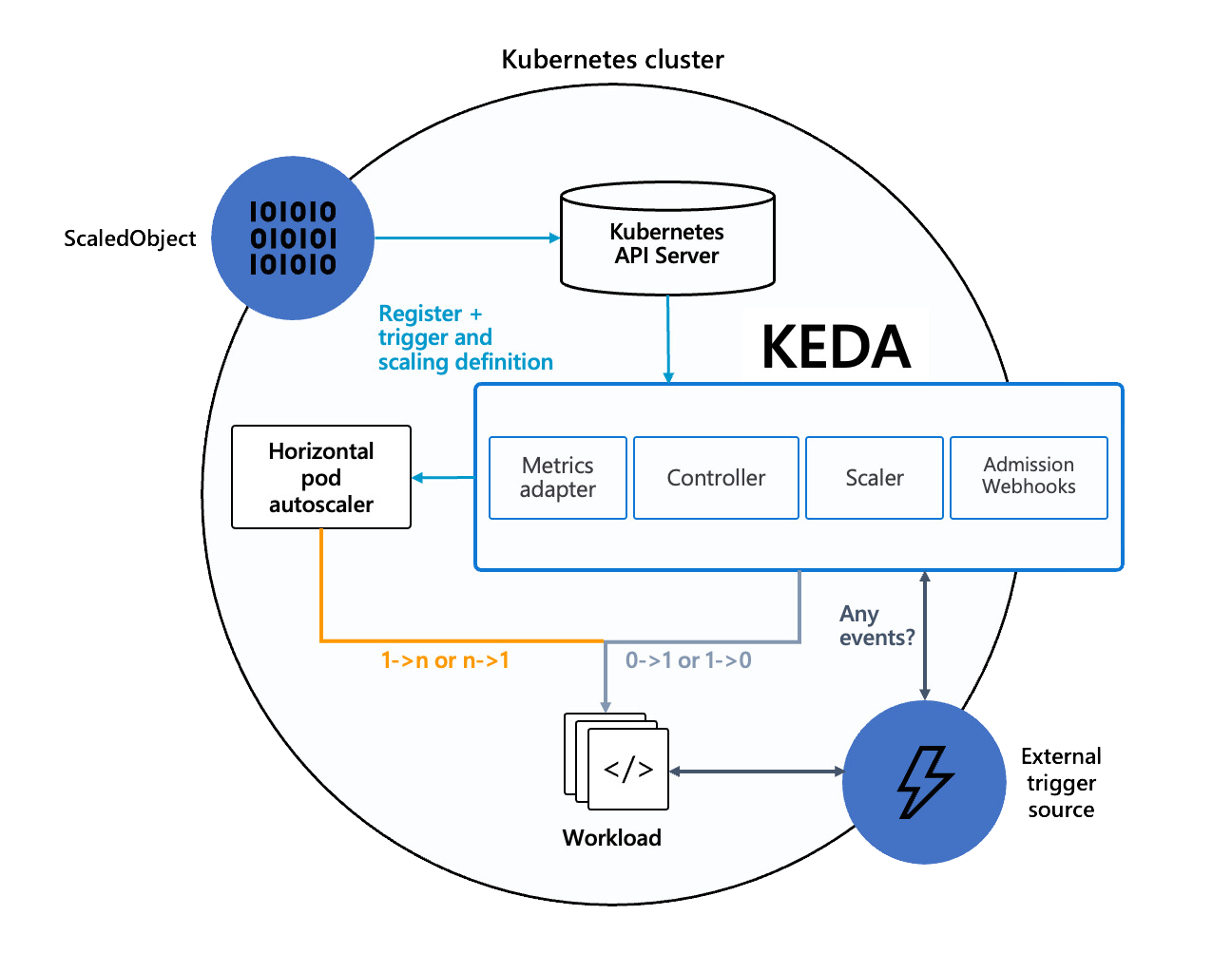
Deploying KEDA in Kubernetes
Prerequisites
- A running Kubernetes cluster (you can use Minikube, GKE, EKS, AKS, or any other cloud/on-prem cluster).
- kubectl is configured to access your cluster.
- Helm installed if you prefer using Helm for deployment.
There are various options that can be used to install KEDA on Kubernetes Cluster.
- Helm
- Operator Hub
- YAML Declarations
For installing via Operator Hub and Yaml declaration, please refer to the following documentation: https://keda.sh/docs/2.15/deploy/
Deploying with Helm
- Add Helm repo
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace
Output
| NAME | READY | STATUS |
|---|---|---|
| pod/keda-admission-webhooks-76967dccbb-x877l | 1/1 | Running |
| pod/keda-operator-554d4b4df9-g7nlg | 1/1 | Running |
| pod/keda-operator-metrics-apiserver-74b745c644-hgn6l | 1/1 | Running |
Deploying a demo application
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
memory: 128Mi
cpu: 100m
apiVersion: v1
kind: Service
metadata:
name: nginx-service
annotations:
metallb.universe.tf/address-pool: production
spec:
type: LoadBalancer
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
You can apply this Kubernetes manifest and describe the newly created deployment.
kubectl apply -f nginx-deployment.yaml
Horizontal pod scaling [HPA] in KEDA
In order to retrieve a pod’s CPU or memory metrics, KEDA uses the Kubernetes Metrics Server. This component is not installed by default on most Kubernetes deployments. You can check this by executing the following command:
kubectl get deploy,svc -n kube-system
We can scale an application by creating a Kubernetes resource called “ScaledObject” (this is a Custom Resource Definition that gets installed when you install KEDA). This resource allows you to define the scaling properties for your application. You can set the cooldown period, the min and max replica count, a reference to the application you want to scale, and which triggers you want to use. In the example below, I’ve created a very simple scaling object. This object scales the application with the name “nginx-deployment” (the demo application we deployed earlier on has the same name) from 2 replicas (min) to 5 replicas (max) based on the CPU utilization. Once the CPU utilization of the 2 “base” replicas is higher than 50%, KEDA will automatically create new replicas in order to distribute the load.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: nginx-scaling
namespace: default
spec:
cooldownPeriod: 60
minReplicaCount: 2
maxReplicaCount: 5
scaleTargetRef:
name: nginx-deployment
triggers:
- type: cpu
metricType: Utilization
metadata:
value: '50'
kubectl apply -f scaledobject.yaml
Check if the scaled object is successfully deployed using by command
Kubectl get ScaledObject -n namespace
Stress testing our application to see KEDA in action
Use stress testing to simulate a load and observe KEDA in action.
kubectl exec -it pod_name -n namespace -- /bin/bash apt-get update apt-get install stress
For CPU utilisation increase, follow this command and monitor pod as increasing replica
stress --cpu 4 --timeout 60s
Check if pod count increased or not.
Kubectl get pod -n name_space
| NAME | READY | STATUS | RESTARTS | AGE |
|---|---|---|---|---|
| nginx-deployment-7b8fdcf699-29mq5 | 1/1 | Running | 0 | 5m32s |
| nginx-deployment-7b8fdcf699-5gwrv | 1/1 | Running | 0 | 15s |
| nginx-deployment-7b8fdcf699-7mjnb | 1/1 | Running | 0 | 15s |
| nginx-deployment-7b8fdcf699-pwpdd | 1/1 | Running | 0 | 5m32s |
After a complete stress test, check the current status of pods.
| NAME | READY | STATUS | RESTARTS | AGE |
|---|---|---|---|---|
| nginx-deployment-7b8fdcf699-29mq5 | 1/1 | Running | 0 | 5m32s |
| nginx-deployment-7b8fdcf699-pwpdd | 1/1 | Running | 0 | 5m32s |
Memory-Based Scaling
The same nginx deployment can also scale based on memory usage. Update the ScaledObject as follows:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: nginx-scaling
namespace: default
spec:
cooldownPeriod: 60
minReplicaCount: 2
maxReplicaCount: 5
scaleTargetRef:
name: nginx-deployment
triggers:
- type: memory
metricType: Utilization
metadata:
value: "50"
Test the memory scaling with:
stress --vm 4 --vm-bytes 2G --timeout 60s
Check pod status and count
kubectl get pods -n <namespace>
| NAME | READY | STATUS | RESTARTS | AGE |
|---|---|---|---|---|
| nginx-deployment-7b8fdcf699-29mq5 | 1/1 | Running | 0 | 5m32s |
| nginx-deployment-7b8fdcf699-5gwrv | 1/1 | Running | 0 | 15s |
| nginx-deployment-7b8fdcf699-7mjnb | 1/1 | Running | 0 | 15s |
| nginx-deployment-7b8fdcf699-pwpdd | 1/1 | Running | 0 | 5m32s |
Stress test complete. Check the pod status
| NAME | READY | STATUS | RESTARTS | AGE |
|---|---|---|---|---|
| nginx-deployment-7b8fdcf699-29mq5 | 1/1 | Running | 0 | 5m32s |
| nginx-deployment-7b8fdcf699-pwpdd | 1/1 | Running | 0 | 5m32s |
Real-World Use Cases
- E-Commerce: Scale during flash sales when order volumes surge.
- IoT Applications: Handle sensor data spikes in real-time.
- Streaming Services: Scale consumers processing Kafka topics dynamically.
Conclusion
KEDA brings the power of event-driven scaling to Kubernetes, making it an indispensable tool for dynamic workloads. Whether you're processing millions of messages or running high-traffic applications, KEDA ensures optimal resource utilization while minimizing costs. Try it out today and unlock the potential of event-driven architecture in your Kubernetes environment!