

Whenever we remove a pod from Kubernetes, what does it do to prevent outside traffic from entering the dying pod? How does the pod internally sense that it is about to be removed and perform a graceful shutdown? And what is the sequence and relationship between these actions and the hook?
In this post, I will first introduce the whole process of pod deletion, and then make hands dirty to verify three scenarios:
- The timing of
postStartandpreStopexecution in the main container of a pod. - How
terminationGracePeriodSecondsaffectpreStopand graceful shutdown? - Whether the API Server can be requested during a Pod graceful shutdown?
Pod Deletion Process

As shown above, when you type kubectl delete pod, the pod record in ETCD will be updated by the API Server, for example, add deletionTimestamp and deletionGracePeriodSeconds. According to the updated ETCD record, the pod is displayed as Terminating status. Next, the pod will carry out two processes in parallel.
- First, the endpoint controller watched the pod is marked as Terminating. Then it will remove the endpoint of the pod from the associated service to prevent external traffic from entering the pod through the service again. At the latest, the endpoint starts getting removed from Kube-proxy, Iptables, Ingress, CoreDNS and all these things hold the endpoint information.
- In the meanwhile,
kubeletis notified of the pod being updated (Terminating). If thepreStopexists, the hook is executed, if not, thekubeletimmediately sends a SIGTERM signal to the main container. Then after waiting for a graceful shutdown period, which is determined by the terminationGracePeriodSeconds with default 30 seconds, the container is forcibly stopped. And finally, the API Server removes the pod from ETCD completely.
Since the endpoint controller flow and the pod shutdown flow are happening independently. Before removing Pod IP from kube-proxy, iptables and others, it may still be in use. At the same time, the main container received the SIGKILL and stopped. Then it will not be able to fulfill these ongoing requests. The solution to the issue is to extend the graceful shutdown period, like kubectl delete pod name — grace-period=100. It adds a bit more gap between the endpoints removed from all the consumers and the Pod deleted.
Scenario 1: The Timing of postStart and preStop Execution
Step1. Create the main container with files main.go, postStart.sh and preStop.sh
postStart=5s preStop=5s termiationGracePeriodSeconds=10s gracefulShutdown=2s
func min(}i(
signalchan t= make(chon os.Signol, 1)
Signal lotify (signalChan, syscall: SIGH, syscall SIGUIT, syscall. SIGTEM, syscall. SIGINT, syscall. SIGSEGY, syscall.
scam)
fat.Printr("s [ 35 ] main container start running \a*, tise.Nou().Foraat("2006-91-02 15:04:05°))
ticker := tine Nevicker(tine. Second)
cout i=
Toop:
for
setece ¢
case sig = <-signachan:
fAUPAAREI("s [%s | receive signals As = Ad \1", tise.No).Foraat ("2606-01-02 15:04:05"), sig.Strina(), sia)
cout =
break toon
case <-ticker.:
fat.printe(* (3a seconds) a, cout)
»
>
fat.Printr("s [ As ] graceful shutdown \W", tine.Nou() Fornat("2986-01-02 15:64:05")
tine.Steep(2 = tine.econd)
fat.Printr("s [ 35 ) sain container finished \n", tine. Now()-Farsat "2005-
3
102 15:08:05%))
main.go
#l{bin/bash
set =e pipefail
echo
ness (date "48Y-ta-4d HAAS")
echo =
echo "start tine: Stine"
> fusc/share/prestop
while ([ second ne 0 11; do
steep 1
tine=s (date "eY-An-Ad MAS")
echo [ stine | prestop is processing.
(second)
done
tiness (date "4Y-ta-td HNIAS")
eco =
cho “end tine: Stine’ >» /usr/sharel/prestap
prestop end: [ stine | =preStop.sh
#1/bin/bash. set pipefail ness (date "4SY-tm-td SH: 14S echo poststart start: [ stine | echo "start tine: Stine" > /usr/share/poststart secondss while [1 $second =ne 0 11; do steep 1 time=s(date "+¥Y-va-%d MHEMHIRS") echo " [ Stine | poststart is processing ((second—)) done. tiness (date "4Y-ta-td AH:AS") echo echo “end tin poststart end: [ stine | + Stine" >> /usr/share/poststart
postStart.sh
Step2. Wrap all the files with Dockerfile
# Stage 1: build the target binaries FROY golang:1.18 AS builder WORKDIR /workspace COPY go.mod go.sun ./ COPY /Lifecycle/ ./Lifecycle/ RUN go build 0 bin/Lifecycle ./lifecycle/main.go # Stage 2: Copy the binaries from the inage builder to the base inage FROW redhat/ubi8-nininal: Latest COPY —from=builder /workspace/bin/Lifecycle /bin/lifecycle COPY ./Lifecycle/hooks/poststart.sh /bin/poststart.sh COPY ./Uifecycle/hooks/prestop.sh /bin/prestop.sh ENTRYPOINT ["/bin/lifecycle"]
Dockerfile
Step3. Deploy Pod with the main container and hooks Dockerfile
apiversion: vi Kinds Pod metadata: name: “lifecycle-deno® spec: terainationGracePeriodseconds: 10 containers: = name: Uifecycle-deso-container image: quay. io/nyan/ Lifecycle: Latest Ufecycle: poststart: , "/bin/poststart.sh > /proc/1/d/1"] command: ['sh", "~c", "/bin/prestop.sh > /proc/1/fd/1"] VoluneHounts: ~ nase: hooks mountPath /usr/share/. Volumes: ~ nan: hooks hostpath: paths fusr/hooks/
sample.yaml
As shown above, we deploy the Pod and delete it after a few seconds. I captured the logging process and plotted the logging flow. where the # indicates that the main container is running.
# [ 2022-08-31 01:28:03 ] main container start running ===================== poststart start: [2022-08-31 01:28:03 ] ===================== #(1) [2022-08-31 01:28:04] poststart is processing... #(2) [2022-08-31 01:28:05 ] poststart is processing... #(3) [2022-08-31 01:28:06 ] poststart is processing... #(4) [2022-08-31 01:28:07 ] poststart is processing... #(5) [2022-08-31 01:28:08 ] poststart is processing... ===================== poststart end: [2022-08-31 01:28:08 ] ===================== #(6) #(7) #(8) #(9) #(10) #(11) #(12) #(13) #(14) #(15) #(16) #(17) #(18) #(19) #(20) #(21) ===================== prestop start: [2022-08-31 01:28:24 ] ===================== #(22) [2022-08-31 01:28:25] prestop is processing... #(23) [2022-08-31 01:28:26 ] prestop is processing... #(24) [2022-08-31 01:28:27 ] prestop is processing... #(25) [ 2022-08-31 01:28:28 ] prestop is processing... #(26) [2022-08-31 01:28:29 ] prestop is processing.. ===================== prestop end: [2022-08-31 01:28:29 ] ===================== # [2022-08-31 01:28:29 ] receive signal: terminated => 15 # [2022-08-31 01:28:29 ] graceful shutdown # [2022-08-31 01:28:31] main container finished
Pod.log
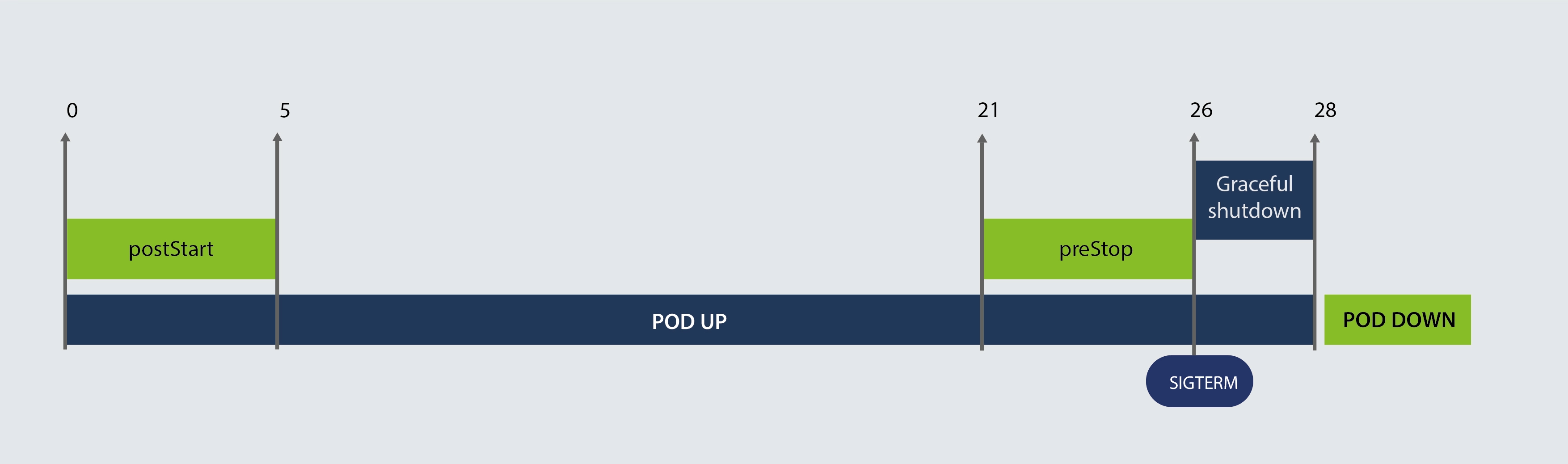
Scenario 1 flow chart
We can see that postStart and the main container are running at the same time. After the preStop comes to an end, the Pod receives a SIGTERM signal. Then the GracefulShutdown starts and when it’s done, The container process ends as expected
It is worth noting that the main container’s GraceShutdown(2s) is less than terminationGracePeriodSeconds(10s), and the main container is shut down gracefully.
Scenario 2: terminationGracePeriodSeconds & preStop & graceful shutdown
Step 1: Extend the preStop to 15 seconds, then the parameters are as follows.
postStart=5s preStop=15s termiationGracePeriodSeconds=10s gracefulShutdown=2s
#!/bin/bash set -e pipefail echo "" time=$(date "+%Y-%m-%d %H:%M:%S") echo "========================== prestop start: [ $time ] ==========================" echo "start time: $time" > /usr/share/prestop second=15 while [[ $second -ne 0 1]; do sleep 1 time=$(date "+%Y-%m-%d %H:M:%S") echo" [ $time ] prestop is processing..." ((second--)) done time=$(date "+%Y-%m-%d %H:%M:%S") echo "========================== prestop end: [ $time ] ==========================" echo "end time: $time" >> /usr/share/prestop
preStop.sh
# [ 2022-08-31 03:28:26 ] main container start running ========================== poststart start: [ 2022-08-31 03:28:27 ] ========================== #(1) [ 2022-08-31 03:28:28 ] poststart is processing... #(2) [ 2022-08-31 03:28:29 ] poststart is processing... #(3) [ 2022-08-31 03:28:30 ] poststart is processing.. #(4) [ 2022-08-31 03:28:31 ] poststart is processing... #(5) [ 2022-08-31 03:28:32 ] poststart is processing... ========================== poststart end: [ 2022-08-31 03:28:32 ] ============================ #(6) #(7) #(8) #(9) #(10) #(11) #(12) #(13) #(14) #(15) #(16) #(17) #(18) #(19) #(20) #(21) #(22) ========================== prestop start: [ 2022-08-31 03:28:49 ] ============================ #(23) [ 2022-08-31 03:28:50 ] prestop is processing... #(24) [ 2022-08-31 03:28:51 ] prestop is processing... #(25) [ 2022-08-31 03:28:52 ] prestop is processing... #(26) [ 2022-08-31 03:28:53 ] prestop is processing.. #(27) [ 2022-08-31 03:28:54 ] prestop is processing... #(28) [ 2022-08-31 03:28:55 ] prestop is processing... #(29) [ 2022-08-31 03:28:56 ] prestop is processing... #(30) [ 2022-08-31 03:28:57 ] prestop is processing.. #(31) [ 2022-08-31 03:28:58 ] prestop is processing... #(32) # [ 2022-08-31 03:28:59 ] receive signal: terminated => 15 # [ 2022-08-31 03:28:59 ] graceful shutdown [ 2022-08-31 03:28:59 ] prestop is processing... [ 2022-08-31 03:29:00 ] prestop is processing... # [ 2022-08-31 03:29:01 ] main container finished
pod.log

We can find that terminationGracePeriodSeconds is the duration between the start of Preston and the receiving of SIGTERM. After that, the preStop continued to work until the main container shut down.
Step2: Set the gracefulShutdown more than termiationGracePeriodSeconds
# [ 2022-08-31 10:40:37 ] main container start running ========================== poststart start: [ 2022-08-31 10:40:37 ] ========================== # (1) [ 2022-08-31 10:40:38 ] poststart is processing... # (2) [ 2022-08-31 10:40:39 ] poststart is processing.. # (3) [ 2022-08-31 10:40:40 ] poststart is processing... # (4) [ 2022-08-31 10:40:41 ] poststart is processing... # (5) [ 2022-08-31 10:40:42 ] poststart is processing... ========================== poststart end: [ 2022-08-31 10:40:42 ] ============================ #(6) #(7) #(8) #(9) #(10) #(11) #(12) ========================== prestop end: [ 2022-08-31 10:40:49 ] ============================== #(13) [ 2022-08-31 10:40:50 ] prestop is processing... #(14) [ 2022-08-31 10:40:51 ] prestop is processing... #(15) [ 2022-08-31 10:40:52 ] prestop is processing... #(16) [ 2022-08-31 10:40:53 ] prestop is processing... #(17) # [ 2022-08-31 10:40:54 ] receive signal: terminated => 15 # [ 2022-08-31 10:40:54 ] graceful shutdown running [ 2022-08-31 10:40:54 ] prestop is processing... # [ 2022-08-31 10:40:55 ] graceful shutdown running [ 2022-08-31 10:40:55 ] prestop is processing... # [ 2022-08-31 10:40:56 ] graceful shutdown running [ 2022-08-31 10:40:56 ] prestop is processing... # [ 2022-08-31 10:40:57 ] graceful shutdown running [ 2022-08-31 10:40:57 ] prestop is processing... ========================== prestop end: [ 2022-08-31 10:40:57 ] ============================== # [ 2022-08-31 10:40:58 ] graceful shutdown running # [ 2022-08-31 10:40:59 ] graceful shutdown running rpc error: code = NotFound desc = an error occurred when try to find container "229ecf2fe42975a00a49e066249ef9ead70a6618c3b625c86eb5bd4a5bf5a717": not found#
pod.log
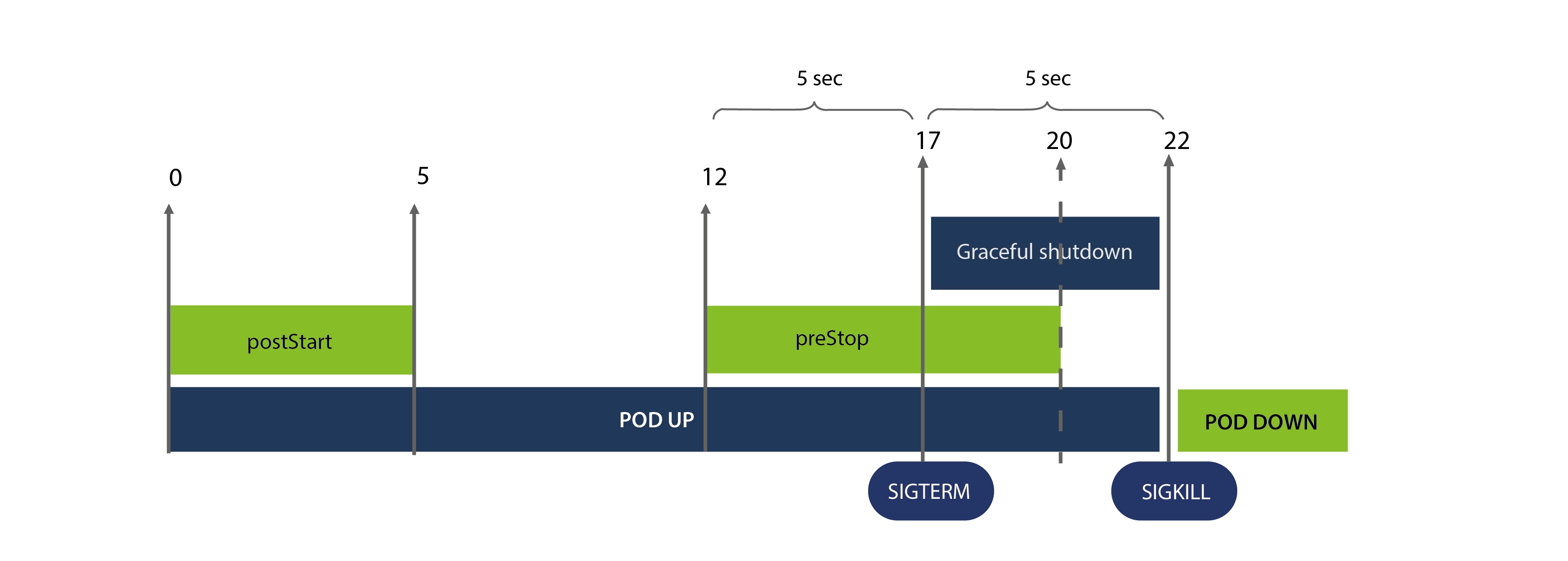
The following conclusions can be drawn from the above logs.
- The timing of receiving the SIGTERM depends on the
preStopandterminationGracePeriodSeconds. In a nutshell, the duration of receiving SIGTERM = Min(preStop,terminationGracePeriodSeconds).
To be specific, ifpreStop < terminationGracePeriodSeconds, then get the SIGTERM after running thepreStop. IfpreStop >= terminationGracePeriodSeconds, then get the SIGTERM after running theterminationGracePeriodSeconds. - After receiving the SIGTERM, The pod begins to shut down, and receiving the SIGKILL stops arbitrarily, with the maximum duration (
terminationGracePeriodSeconds).
Scenario 3: Request the API Server during the Pod graceful shutdown
postStart=5 preStop=5 termiationGracePeriodSeconds=8 gracefulShutdown=10
loop:
for {
select {
case sig := <-signalChan:
fmt. Printf("# [ %s ] receive signal: %s => %d \n", time.Now (). Format("2006-01-02 15:04:05"), sig.String(), sig)
count = 0
break loop
case <-ticker. C:
count++
fmt. Printf(" #(%d)", count)
}
}
fmt.Printf("# [ %s] graceful shudown >>>>>>>>>>>>>>> \n", time.Now ().Format("2006-01-02 15:04:05"))
for i:= 0; i < 10; i++ {
time. Sleep (1 * time. Second)
count++
sa, _ := clientset. CoreV1 (). ServiceAccounts("default").Get(context. TODO(), "default", metav1.GetOptions{})
fmt.Printf(" #(%d) => service account: %s \n", count, sa.Name)
}
fmt.Printf("# [ %s ] main container finished \n", time.Now().Format("2006-01-02 15:04:05"))
}
main.go
Since the pod needs to connect to the API Server, It needs to give some privileges to the Pod’sServiceAccount in the default namespace named default.
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/vi
metadata:
name: default-user-clusteradnin
namespace: default
subjects:
- kind: ServiceAccount
name: default
namespace: default
roleRe:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
# [ 2022-08-31 13:35:12 ] main container start running ========================== poststart start: [ 2022-08-31 13:35:12 ] ============================== #(1) [ 2022-08-31 13:35:13 ] poststart is processing... #(2) [ 2022-08-31 13:35:14 ] poststart is processing... #(3) [ 2022-08-31 13:35:15 ] poststart is processing... #(4) [ 2022-08-31 13:35:16 ] poststart is processing... #(5) [ 2022-08-31 13:35:17 ] poststart is processing... ========================== poststart end: [ 2022-08-31 13:35:17 ] ============================== #(6) #(7) #(8) #(9) #(10) #(11) #(12) ========================== prestop start: [ 2022-08-31 13:35:25 ] ============================== #(13) [ 2022-08-31 13:35:26 ] prestop is processing... #(14) [ 2022-08-31 13:35:27 ] prestop is processing... #(15) [ 2022-08-31 13:35:28 ]prestop is processing... #(16) [ 2022-08-31 13:35:29 ] prestop is processing... #(17) [ 2022-08-31 13:35:30 ] prestop is processing... =============================== prestop end: [ 2022-08-31 13:35:30 ] ============================== # [ 2022-08-31 13:35:30 ] receive signal: terminated => 15 # [ 2022-08-31 13:35:30 ] graceful shudown >>>>>>>>> #(1) => service account: default #(2) => service account: default #(3) => service account: default #(4) => service account: default #(5) => service account: default #(6) => service account: default #(7) => service account: default rpc error: code = Not Found desc = an error occurred when try to find container "1ba21311a518cf9a3b00803d47e78fc29b63dca09e5f17bf705cf41183b741b6": not found#
pod.log

At last, we verified the Pod is always able to request API Server during the graceful shutdown.
Demo Source Code


