High availability is a cornerstone of modern application design, ensuring that services remain operational even when infrastructure components fail. In Kubernetes, one effective way to achieve this is by distributing Pods across multiple nodes and availability zones (AZs). This blog explores how Pod Topology Spread Constraints, combined with nodeSelector and tolerations, can be used to distribute Pods across failure domains for maximum resilience.
The aim is to:
- Distribute Pods Across Nodes: Avoid overloading any single node, improving fault tolerance.
- Distribute Pods Across Availability Zones: Prevent application downtime in case of AZ failures.
- Declarative Configuration: Ensure easy scaling and seamless configuration management as the cluster grows.
How It Works
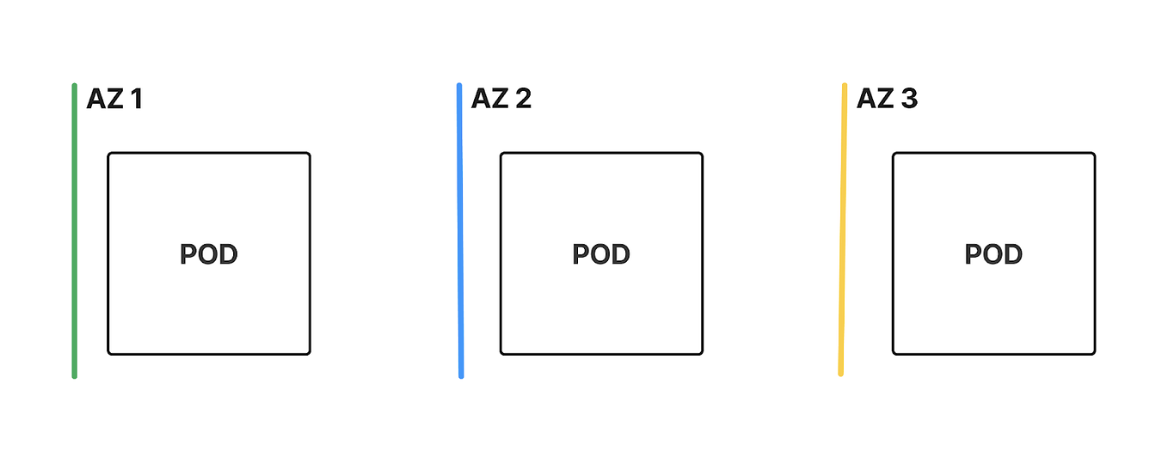
- AZ-Level Distribution - Using topologySpreadConstraints, we ensure that Pods are evenly distributed across different AZs by referencing the label topology.kubernetes.io/zone. Setting maxSkew: 1 ensures no more than a one-Pod difference between any two AZs.
- Node-Level Distribution - To avoid overloading any node, we use another topologySpreadConstraint with the topologyKey: kubernetes.io/hostname, which ensures Pods are distributed evenly across nodes within each AZ.
- Tolerations for Tainted Nodes - Tolerations allow Pods to be scheduled on nodes that have specific taints, like app-name/app-taint=true:NoSchedule, ensuring separation between environments (e.g., production and development).
- Targeted Scheduling with nodeSelector
- nodeSelector - ensures Pods are scheduled on nodes that meet certain hardware specifications (e.g., 4 CPUs, amd64 architecture) to optimize performance.
Kubernetes YAML Configuration Example:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
spec:
replicas: 5
selector:
matchLabels:
app.kubernetes.io/name: "example-app"
app.kubernetes.io/instance: "example-app"
template:
metadata:
labels:
app.kubernetes.io/name: "example-app"
app.kubernetes.io/instance: "example-app"
spec:
nodeSelector:
karpenter.k8s.aws/instance-category: c
karpenter.k8s.aws/instance-cpu: "4"
kubernetes.io/arch: amd64
tolerations:
- key: "app-name/app-taint"
operator: "Equal"
value: "true"
effect: "NoSchedule"
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app.kubernetes.io/name: "example-app"
app.kubernetes.io/instance: "example-app"
- maxSkew: 1
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app.kubernetes.io/name: "example-app"
app.kubernetes.io/instance: "example-app"
Key Sections Breakdown
- nodeSelector: Ensures Pods are scheduled on nodes with at least 4 CPUs and amd64 architecture.
- Tolerations: Allows Pods to be scheduled on nodes with the app-name/app-taint=true taint, ensuring proper environment separation.
- topologySpreadConstraints (AZ-Level): Ensures Pods are evenly distributed across AZs with a maximum difference of one Pod per AZ.
- topologySpreadConstraints (Node-Level): Ensures Pods are evenly distributed across nodes within each AZ.
Expected Outcome
With this configuration:
- Even Distribution Across AZs: Pods will be evenly distributed between availability zones, preventing imbalance.
- Even Distribution Across Nodes: Pods are distributed across nodes, avoiding overload on any single node.
- Tolerated Nodes: Pods will only be scheduled on nodes that match the specified taint, ensuring environment separation.
- Hardware-Specific Scheduling: Pods are scheduled on nodes that meet specific hardware requirements, improving performance.
Conclusion
By using topologySpreadConstraints, nodeSelector, and tolerations, you can enhance the availability and performance of your Kubernetes applications. This setup ensures that Pods are distributed efficiently across nodes and availability zones, optimizing both fault tolerance and resource utilization. With declarative configuration, your cluster can scale smoothly and remain resilient as your infrastructure evolves.